DeepBanana
This project is a part of Udacity’s Deep Reinforcement Learning Nanodegree Program
Our main directive is to create a Reinforcement Learning agent to solve Unity Banana environment.
Media
A fully trained agent
Environment Description
The environment was provided by Udacity, built on top of Unity Machine Learning Agents Toolkit.
In this environment, the agent’s task is to collect as many yellow bananas as possible, while avoiding blue bananas. Collecting a yellow banana grants the agent +1 reward, and -1 reward if the agent collects a blue banana.
The state space has 37 dimensions and contains the agent’s velocity, along with ray-based perception of objects around agent’s forward direction. Given this information, the agent has to learn how to best select actions. Four discrete actions are available, corresponding to:
0- move forward.1- move backward.2- turn left.3- turn right.
The task is episodic, and in order to solve the environment, the agent must get an average score of +13 over 100 consecutive episodes.
Unity is not needed to run my project, I will be providing the environment files below:
These files are provided as part of the project description by Udacity
Please note that if you want to run my model, you will need to download the environment file corresponds to your Operating System, and unzip it in the same level as the cloned repository.
Getting Started
After downloading the environment file and unzipping it to the correct location. You can start by
creating and activating a new virtual environment (Python 3.6) to run my project.
I used virtualenv
$ virtualenv drl
$ source drl/bin/activate
Then we can start installing the dependencies needed
$ cd python/
$ pip install .
Then to train the agent, you need to make a small modification to main.py file. Open it up and under line 22
where I defined the environment, the file_name parameter to the function call need to have the correct path
to the environment file. After that is done, you can watch the agent trains in real time with
$ python main.py <Double>
Where <Double> can take either true (using Double DQN) or false (regular DQN)
Alternatively, you can download my pretrained weights from here,
place it in the same directory with evaluation.py and run
$ python evaluation.py
to watch a fully trained agent plays the game.
Technical Details
DQN and Double DQN was implemented. In DQN, I used two identical neural networks (described below) to update weights and improve the accumulated return. In Double DQN, I also used two identical neural networks, but I use one to update the other.
Experience Replay (EP) was also implemented, the idea of EP is to interact with the environment, store the experiences in a dictionary, and sample randomly from this dictionary to learn.
For neural network architecture, I used a 3 layers fully connected perceptron network to map from the state to action values. Each hidden layer consists of 128 fully connected units.
Results
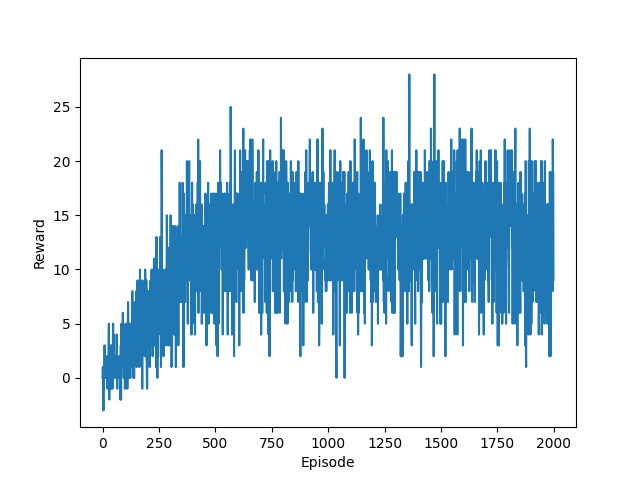
Accumulated return over 2000 episodes
My agent was able to solve the environment in 503 episodes for regular DQN, and 381 episodes for Double DQN network.
Future Work
There are many aspects in which I can improve this project. Implementing dueling DQN or prioritized experience replay would likely improve the number of episodes until solved.
Now that this environment is solved, I should try out solving the same game, but with a different state representation. Representing the state as raw pixels would be more realistic since raw pixels are what we see, and we should allow the agent to see the same.
Source Code
The full source code for the project can be found here