Auto Image Captioning
I created an auto image captioning model using data from the Microsoft Common Objects in COntext (MS COCO) dataset. This dataset is commonly used to train and benchmark object detection, segmentation, and captioning algorithms. You can learn more about the dataset here.
This project was part of the Udacity Computer Vision Nanodegree Program.
Network Architecture
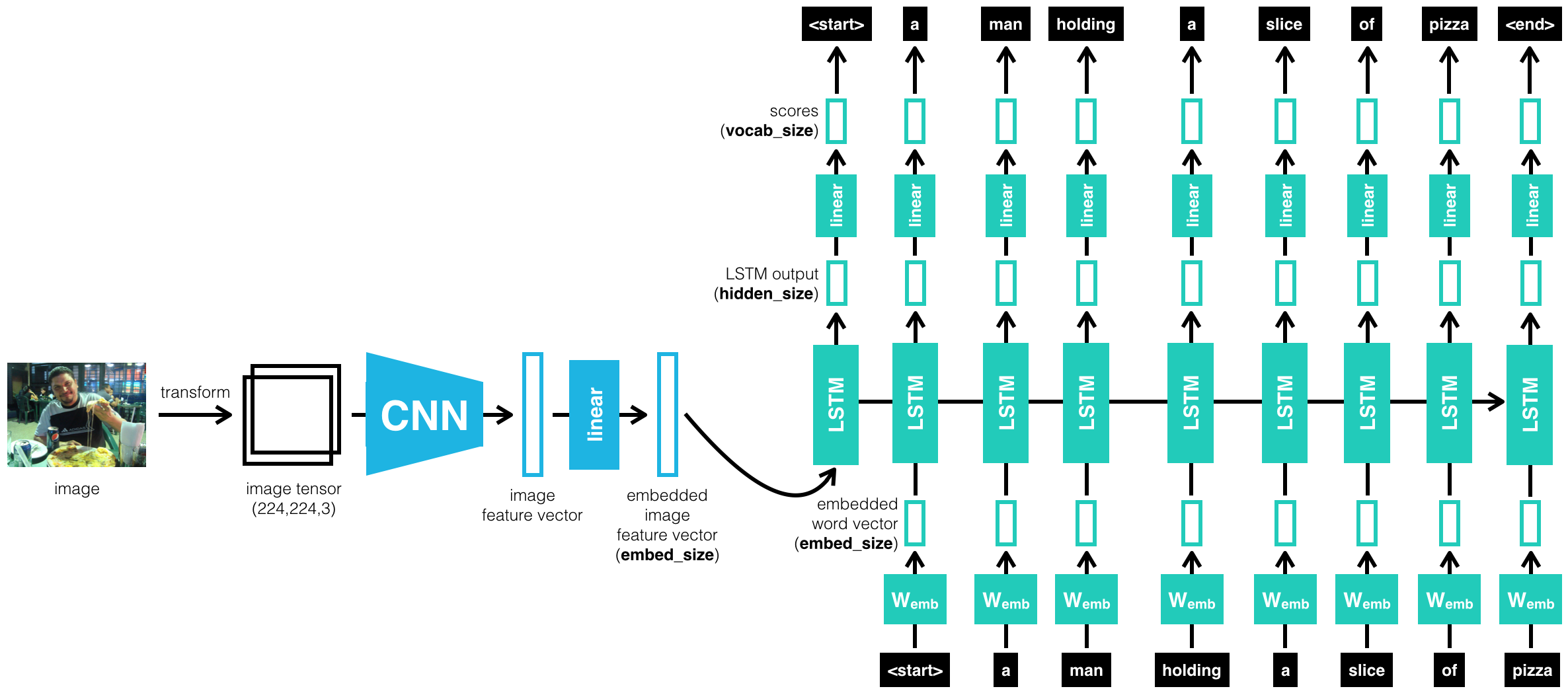
CNN - RNN architecture
The architecture that I implemented was a Convolutional Neural Network (CNN) followed by a Recurrent Neural Network (RNN) with Long-Short Term Memory (LSTM) cells.
The CNN was used to extract a feature vector from the input image, then that feature vector is fed into the RNN to sequentially output the caption word by word.